

Execute multiple AI approaches or strategies simultaneously and return the result from whichever completes first successfully. This pattern is ideal when you have multiple ways to solve the same problem and want to minimize latency by racing them against each other. Useful for:Documentation Index
Fetch the complete documentation index at: https://restate-6d46e1dc-pavel-xumzvomylzon.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- Querying multiple AI models (e.g., GPT-4, Claude, Gemini) and returning the fastest response
- Running different agents, prompts or strategies in parallel and using the first successful outcome
How does Restate help?
The benefits of using Restate for competitive racing patterns are:- Durable coordination: Restate turns Promises/Futures into durable, distributed constructs that persist across failures and process restarts. Race multiple approaches and return the first successful result.
- Cancel slow tasks: Failed or slower approaches can be cancelled, preventing resource waste
- Serverless scaling: Deploy racing strategies on serverless infrastructure for automatic scaling while the main process remains suspended
- Works with any LLM SDK (Vercel AI, LangChain, LiteLLM, etc.) and any programming language supported by Restate (TypeScript, Python, Go, etc.).
Example
When you need a quick response and have access to multiple AI models, race them against each other to get the fastest result: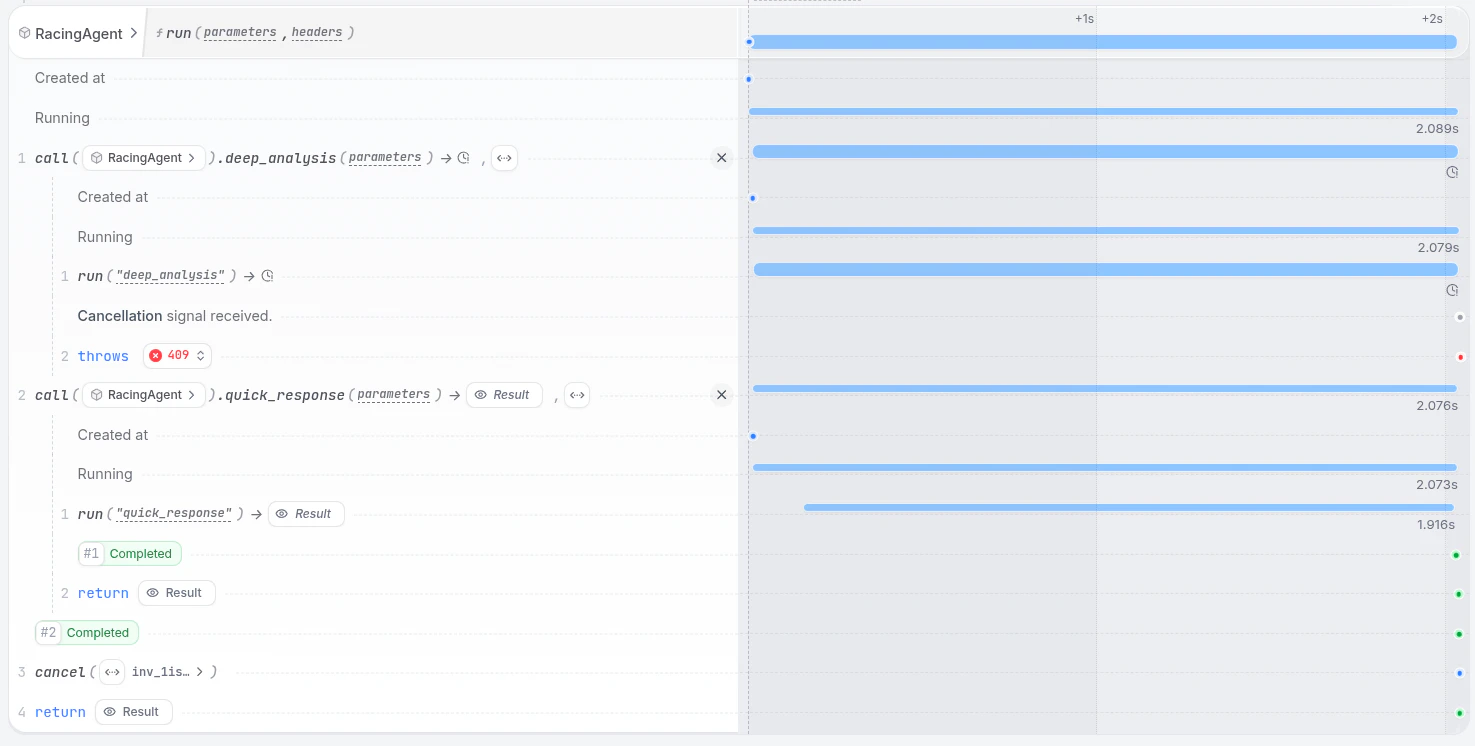
Run the example
Run the example
Requirements
- AI SDK of your choice (e.g., OpenAI, LangChain, Pydantic AI, LiteLLM, etc.) to make LLM calls.
- API key for your model provider.
Start the Service
Export the API key of your model provider as an environment variable and then start the agent. For example, for OpenAI:
Send a request
In the UI (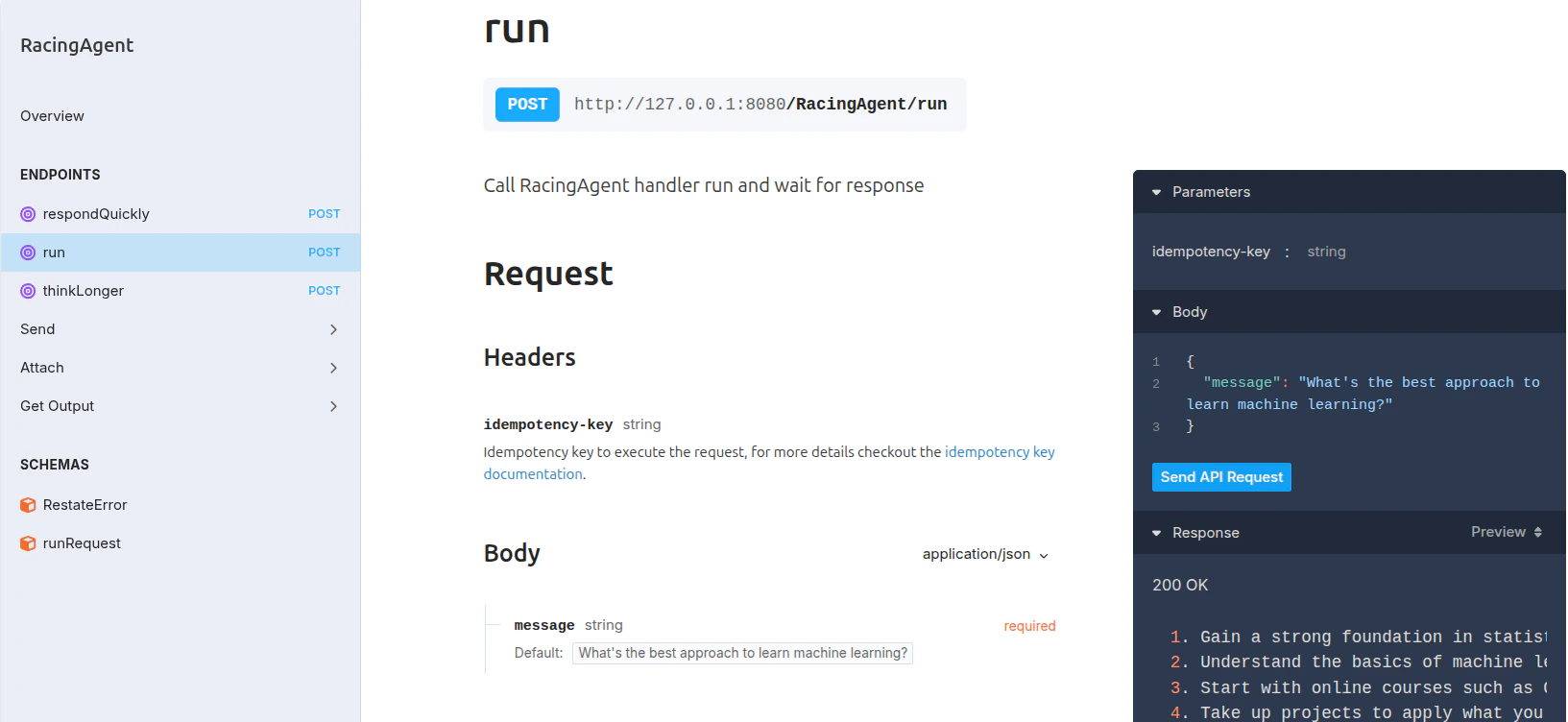
http://localhost:9070), click on the run handler of the RacingAgent service to open the playground and send a prompt to race multiple models: